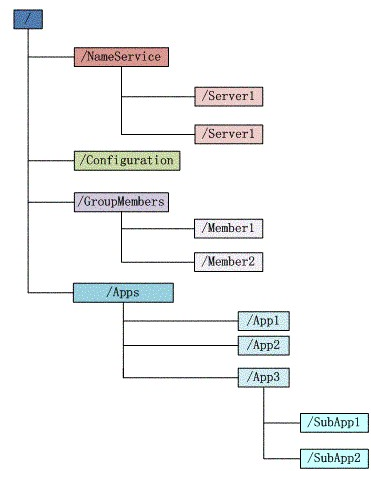
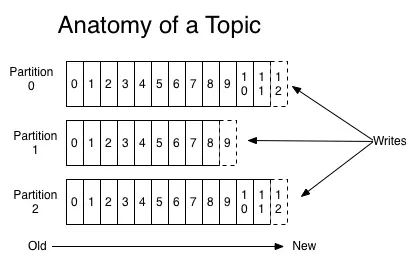
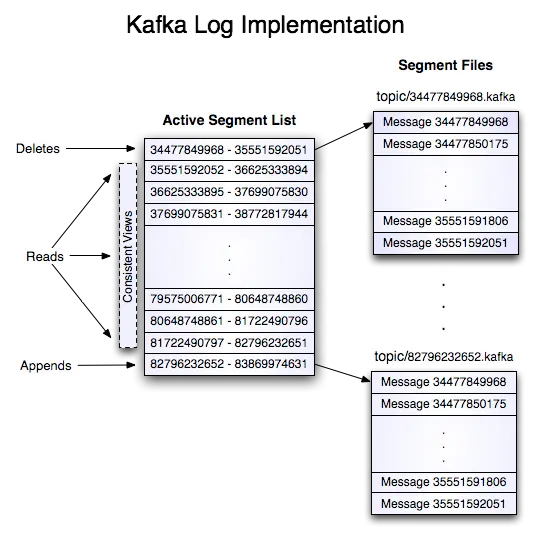
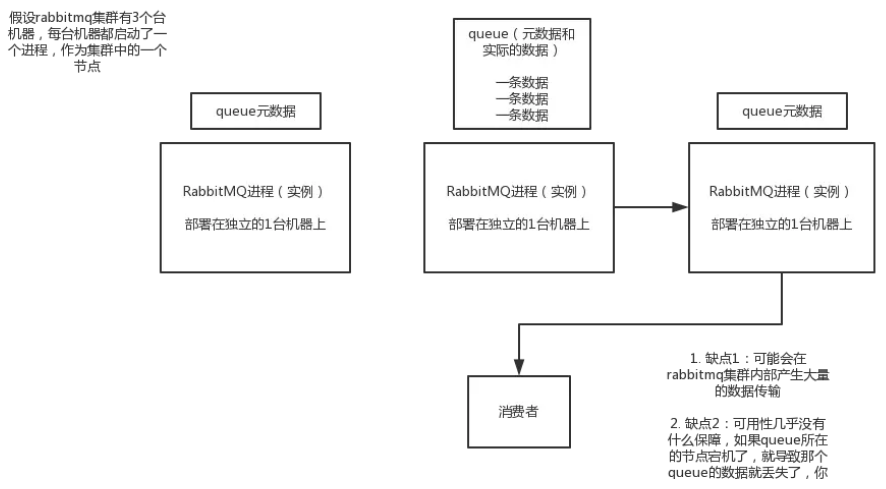
S 强制操作系统将文件刷新到磁盘之前的时间(秒) 在系统崩溃的情况下,最多会丢失 M 条消息或 S 秒的数据。
读
通过给出消息的偏移量(offset)和最大块大小(S)来读取数据。返回一个缓冲区为 S 大小的消息迭代器,S 应该大于任何单个消息的大小,如果消息异常大,则可以多次重试读取,每次都将缓冲区大小加倍,直到成功读取消息为止。可以指定最大消息大小和缓冲区大小,以使服务器拒绝大于某个大小的消息。读取缓冲区可能以部分消息结束,这很容易被大小分隔检测到。
以转账为例:将账户 X 的余额加 100 元。 在这个例子中,我们可以通过改造业务逻辑,让它具备幂等性。 首先,我们可以限定,对于每个转账单每个账户只可以执行一次变更操作,在分布式系统中,这个限制实现的方法非常多,最简单的是我们在数据库中建一张转账流水表,这个表有三个字段:转账单 ID、账户 ID 和变更金额,然后给转账单 ID 和账户 ID 这两个字段联合起来创建一个唯一约束,这样对于相同的转账单 ID 和账户 ID,表里至多只能存在一条记录。 这样,我们消费消息的逻辑可以变为:“在转账流水表中增加一条转账记录,然后再根据转账记录,异步操作更新用户余额即可。”在转账流水表增加一条转账记录这个操作中,由于我们在这个表中预先定义了“账户 ID 转账单 ID”的唯一约束,对于同一个转账单同一个账户只能插入一条记录,后续重复的插入操作都会失败,这样就实现了一个幂等的操作。我们只要写一个 SQL,正确地实现它就可以了。 基于这个思路,不光是可以使用关系型数据库,只要是支持类似“INSERT IF NOT EXIST”语义的存储类系统都可以用于实现幂等,比如,我们可以用 Redis 的 SETNX 命令来替代数据库中的唯一约束,来实现幂等消费。
为更新的数据设置前置条件
另外一种实现幂等的思路是,给数据变更设置一个前置条件,如果满足条件就更新数据,否则拒绝更新数据,在更新数据的时候,同时变更前置条件中需要判断的数据。 这样,重复执行这个操作时,由于第一次更新数据的时候已经变更了前置条件中需要判断的数据,不满足前置条件,则不会重复执行更新数据操作。 比如,刚刚我们说过,“将账户 X 的余额增加 100元”这个操作并不满足幂等性,我们可以把这个操作加上一个前置条件,变为:“如果账户 X 当前的余额为 500元,将余额加 100元”,这个操作就具备了幂等性。 对应到消息队列中的使用时,可以在发消息时在消息体中带上当前的余额,在消费的时候进行判断数据库中,当前余额是否与消息中的余额相等,只有相等才执行变更操作。 但是,如果我们要更新的数据不是数值,或者我们要做一个比较复杂的更新操作怎么办?用什么作为前置判断条件呢? 更加通用的方法是,给我们的数据增加一个版本号属性,每次更数据前,比较当前数据的版本号是否和消息中的版本号一致,如果不一致就拒绝更新数据,更新数据的同时将版本号 +1,一样可以实现幂等更新。
记录并检查操作
如果上面提到的两种实现幂等方法都不能适用于我们的场景,我们还有一种通用性最强,适用范围最广的实现幂等性方法:记录并检查操作,也称为“Token 机制或者 GUID(全局唯一ID)机制”,实现的思路特别简单:在执行数据更新操作之前,先检查一下是否执行过这个更新操作。 具体的实现方法是,在发送消息时,给每条消息指定一个全局唯一的 ID,消费时,先根据这个 ID 检查这条消息是否有被消费过,如果没有消费过,才更新数据,然后将消费状态置为已消费。 原理和实现是不是很简单?其实一点儿都不简单,在分布式系统中,这个方法其实是非常难实现的。 首先,给每个消息指定一个全局唯一的 ID 就是一件不那么简单的事儿,方法有很多,但都不太好同时满足简单、高可用和高性能,或多或少都要有些牺牲。更加麻烦的是,在“检查消费状态,然后更新数据并且设置消费状态”中,三个操作必须作为一组操作保证原子性,才能真正实现幂等,否则就会出现 Bug。
以转账为例:将账户 X 的余额加 100 元。 在这个例子中,我们可以通过改造业务逻辑,让它具备幂等性。 首先,我们可以限定,对于每个转账单每个账户只可以执行一次变更操作,在分布式系统中,这个限制实现的方法非常多,最简单的是我们在数据库中建一张转账流水表,这个表有三个字段:转账单 ID、账户 ID 和变更金额,然后给转账单 ID 和账户 ID 这两个字段联合起来创建一个唯一约束,这样对于相同的转账单 ID 和账户 ID,表里至多只能存在一条记录。 这样,我们消费消息的逻辑可以变为:“在转账流水表中增加一条转账记录,然后再根据转账记录,异步操作更新用户余额即可。”在转账流水表增加一条转账记录这个操作中,由于我们在这个表中预先定义了“账户 ID 转账单 ID”的唯一约束,对于同一个转账单同一个账户只能插入一条记录,后续重复的插入操作都会失败,这样就实现了一个幂等的操作。我们只要写一个 SQL,正确地实现它就可以了。 基于这个思路,不光是可以使用关系型数据库,只要是支持类似“INSERT IF NOT EXIST”语义的存储类系统都可以用于实现幂等,比如,我们可以用 Redis 的 SETNX 命令来替代数据库中的唯一约束,来实现幂等消费。
为更新的数据设置前置条件
另外一种实现幂等的思路是,给数据变更设置一个前置条件,如果满足条件就更新数据,否则拒绝更新数据,在更新数据的时候,同时变更前置条件中需要判断的数据。 这样,重复执行这个操作时,由于第一次更新数据的时候已经变更了前置条件中需要判断的数据,不满足前置条件,则不会重复执行更新数据操作。 比如,刚刚我们说过,“将账户 X 的余额增加 100元”这个操作并不满足幂等性,我们可以把这个操作加上一个前置条件,变为:“如果账户 X 当前的余额为 500元,将余额加 100元”,这个操作就具备了幂等性。 对应到消息队列中的使用时,可以在发消息时在消息体中带上当前的余额,在消费的时候进行判断数据库中,当前余额是否与消息中的余额相等,只有相等才执行变更操作。 但是,如果我们要更新的数据不是数值,或者我们要做一个比较复杂的更新操作怎么办?用什么作为前置判断条件呢? 更加通用的方法是,给我们的数据增加一个版本号属性,每次更数据前,比较当前数据的版本号是否和消息中的版本号一致,如果不一致就拒绝更新数据,更新数据的同时将版本号 +1,一样可以实现幂等更新。
记录并检查操作
如果上面提到的两种实现幂等方法都不能适用于我们的场景,我们还有一种通用性最强,适用范围最广的实现幂等性方法:记录并检查操作,也称为“Token 机制或者 GUID(全局唯一ID)机制”,实现的思路特别简单:在执行数据更新操作之前,先检查一下是否执行过这个更新操作。 具体的实现方法是,在发送消息时,给每条消息指定一个全局唯一的 ID,消费时,先根据这个 ID 检查这条消息是否有被消费过,如果没有消费过,才更新数据,然后将消费状态置为已消费。 原理和实现是不是很简单?其实一点儿都不简单,在分布式系统中,这个方法其实是非常难实现的。 首先,给每个消息指定一个全局唯一的 ID 就是一件不那么简单的事儿,方法有很多,但都不太好同时满足简单、高可用和高性能,或多或少都要有些牺牲。更加麻烦的是,在“检查消费状态,然后更新数据并且设置消费状态”中,三个操作必须作为一组操作保证原子性,才能真正实现幂等,否则就会出现 Bug。