利用 ZooKeeper 可以非常方便构建一系列分布式应用中都会涉及到的核心功能。
命名服务
命名服务是指通过指定的名字来获取资源或者服务的地址,利用 ZooKeeper 创建一个全局的路径,即是唯一的路径,这个路径就可以作为一个名字,指向集群中的机器,提供的服务的地址,或者一个远程的对象等等。
ZooKeeper 的命名服务有以下两个应用方面:
- 提供类 JNDI 功能,可以把系统中各种服务的名称、地址以及目录信息存放在 ZooKeeper,需要的时候去 ZooKeeper 中读取。
- 制作分布式的序列号生成器。
数据发布/订阅
数据发布/订阅的一个常见的场景是配置中心:发布者把数据发布到 ZooKeeper 的一个或一系列的节点上,供订阅者进行数据订阅,达到动态获取数据的目的。
配置信息一般有几个特点:
- 数据量小的 KV
- 数据内容在运行时会发生动态变化
- 集群机器共享,配置一致
思路:
ZooKeeper 采用的是推拉结合的方式:
- 推: 服务端会推给注册了监控节点的客户端 Watcher 事件通知
- 拉: 客户端获得通知后,然后主动到服务端拉取最新的数据
数据发布/订阅的另一个常见的场景是服务注册中心,不过由于 ZooKeeper 是基于 CP 原则构建的,因此不适合做服务注册与发现。
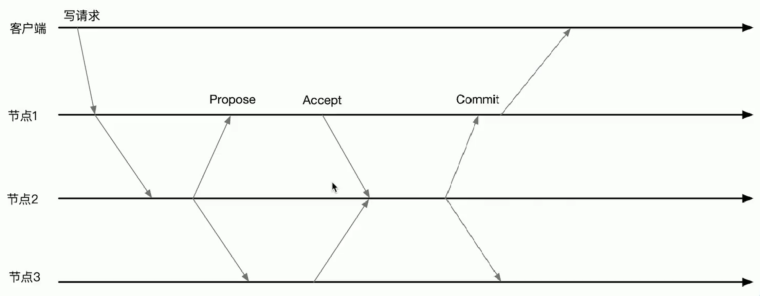
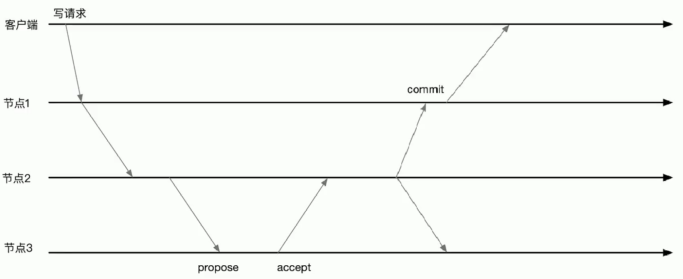
分布式锁
分布式锁是控制分布式系统间同步访问共享资源的一种方式。如果不同的系统或同一个系统的不同主机之间共享了同一个资源,那么访问这些资源的时候,需要使用互斥的手段来防止彼此之间的干扰,以保证一致性,这种情况就需要使用分布式锁。
思路:
使用临时顺序 znode 来表示获取锁的请求,创建最小后缀数字 znode 的用户成功拿到锁。
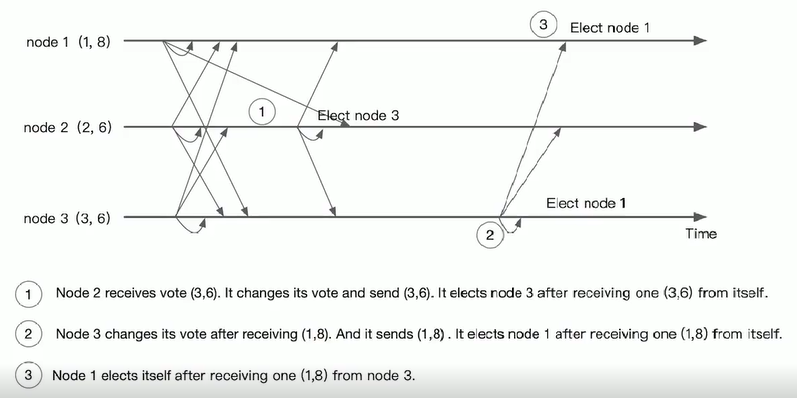
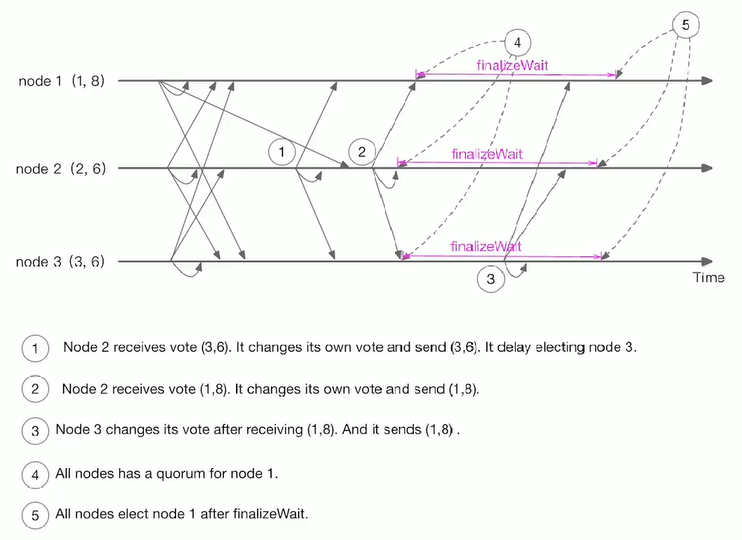
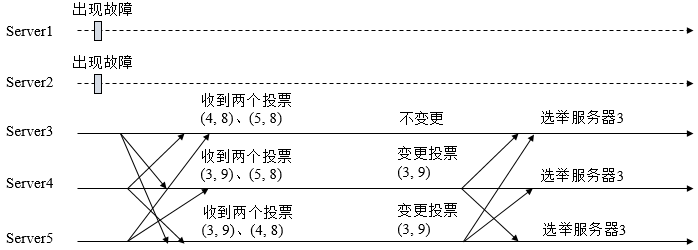
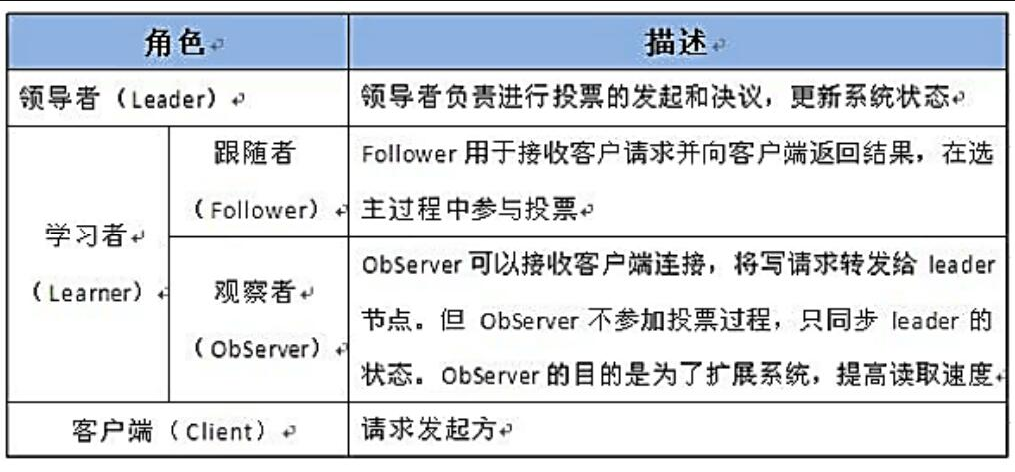
Master 选举
Master 选举,就是在众多机器或服务中,选举出一个最终“决定权”的领导者,来独立完成一项任务。比如有一项服务是需要对外提供服务,但是要保证高可用,我们就机会进行服务的多项部署,也就是做了一些备份,提高系统的可用性。一旦我们的主服务挂了,我们可以让其它的备份服务进行重新选举,这样我们就能使整个系统不会因服务的挂掉而造成服务不可用。
思路:
在 ZooKeeper中,有两种方式可以实现 Master 选举:
- 谁先创建 master 临时节点,谁就是 master,当一个 master 挂掉了,master 节点就消失了,别的节点就会监听到,就会继续去创建 master 临时节点,以此类推,利用 Zookeeper 的两个特点(一个节点只能成功创建一次、利用监听的机制)
- 在 master 下面创建临时有序节点,那个节点最小,那个就是 master,节点挂掉,下面那个临时节点就会监听到上面的临时节点挂掉了,从而取代成为 master,以此类推,(利用 Zookeeper 创建节点临时有序的特性)
分布式协调/通知
分布式协调/通知是将不同的分布式组件有机结合起来的关键所在。对于一个在多台机器上部署运行的应用而言,通常需要一个协调者(Coordinator)来控制整个系统的运行流程,例如分布式事务的处理、机器间的相互协调等。同时,引入这样一个协调者,便于将分布式协调的职责从应用中分离出来,从而大大减少系统之间的耦合性,而且能够显著提高系统的可扩展性。
协调/通知机制通常有两种方式:
系统调度模式:操作人员发送通知实际是通过控制台改变某个节点的状态,然后 Zookeeper 将这些变化发送给注册了这个节点的 Watcher 的所有客户端。
工作汇报模式:这个情况是每个工作进程都在某个目录下创建一个临时节点,并携带工作的进度数据。这样汇总的进程可以监控目录子节点的变化获得工作进度的实时的全局情况。
思路:
用 Zookeeper 的 watcher 注册和异步通知功能,通知的发送者创建一个节点,并将通知的数据写入的该节点;通知的接受者则对该节点注册 watch,当节点变化时,就算作通知的到来。
集群管理
所谓集群管理,包括集群监控与集群控制两大块,前者侧重对集群运行时状态的收集,后者则是对集群进行操作与控制。在日常开发和运维过程中,我们经常会有类似于如下的需求:
- 希望知道当前集群中究竟有多少机器在工作
- 对集群中每台机器的运行时状态进行数据收集
- 对集群中机器进行上下线操作
思路:
ZooKeeper 具有以下两大特性:
- 客户端如果对 ZooKeeper 的一个数据节点注册 Watcher 监听,那么当该数据节点的内容或是其子节点列表发生变更时,ZooKeeper 服务器就会向订阅的客户端发送变更通知。
- 对在 ZooKeeper 上创建的临时节点,一旦客户端与服务器之间的会话失效,那么该临时节点也就被自动清除。
利用 ZooKeeper 的这两大特性,我们可以很方便地实现集群机器存活性监控的系统。
负载均衡
负载均衡是一种手段,用来把对某种资源的访问分摊给不同的设备,从而减轻单点的压力。
我们可以自定义一个负载均衡算法,在每个请求过来时从 ZooKeeper 服务器中获取当前集群服务器列表,根据算法选出其中一个服务器来处理请求。
分布式队列
使用 ZooKeeper 来实现分布式队列,分为两大类:
思路:
- 首先利用 Zookeeper 中临时顺序节点的特点
- 当生产者创建节点生产时,需要判断父节点下临时顺序子节点的个数,如果达到了上限,则阻塞等待;如果没有达到,就创建节点。
- 当消费者获取节点时,如果父节点中不存在临时顺序子节点,则阻塞等待;如果有子节点,则获取执行自己的业务,执行完毕后删除该节点即可。
- 获取时获取最小值,保证 FIFO 特性。
虽然 ZooKeeper 可以用来实现分布式队列,但是并不建议使用,原因有如下几点:
- ZooKeeper 对于传输数据有一个 1MB 的大小限制,这就意味着实际中 ZooKeeper 节点 ZNodes 必须设计的很小,但实际中队列通常都存放着数以千计的消息。
- 如果有很多大的 ZNodes 会严重拖慢的 ZooKeeper 启动过程,包括 ZooKeeper 节点之间的同步过程,如果真要用 ZooKeeper 当队列,最好去调整 initLimit 与 syncLimit 参数。
- 如果一个 ZNode 过大,也会导致清理变得困难,也会导致 getChildren() 方法失败,Netflix 不得不设计一个特殊的机制来处理这个大体积的 ZNode。
- 如果 ZooKeeper 中某个 node 下有数千子节点,也会严重拖累 ZooKeeper 性能。
- ZooKeeper 中的数据都会放置在内存中。
参考资料
- ZooKeeper 的应用场景