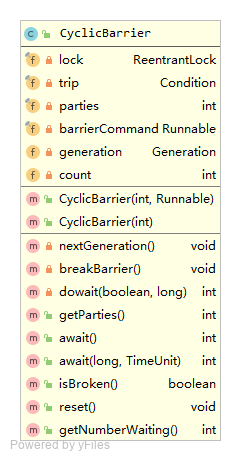
privateintdowait(boolean timed, long nanos) throws InterruptedException, BrokenBarrierException, TimeoutException { // 利用可重入锁,保证同时只有一个线程能进入 final ReentrantLock lock = this.lock; lock.lock(); try { final Generation g = generation;
if (g.broken) thrownew BrokenBarrierException();
if (Thread.interrupted()) { breakBarrier(); thrownew InterruptedException(); }
// 每次调用该方法,count自减 int index = --count; // 等于0时,表示所有线程都已到达屏障 if (index == 0) { // tripped boolean ranAction = false; try { // 如果构造函数有传入command,就执行 final Runnable command = barrierCommand; if (command != null) command.run(); ranAction = true; // 唤醒所有等待线程,并重置 nextGeneration(); return0; } finally { if (!ranAction) breakBarrier(); } }
// loop until tripped, broken, interrupted, or timed out // 所有线程没有全部到达屏障时 for (;;) { try { // 如果未设置超时,调用Contion.await(),将线程放入等待队列 if (!timed) trip.await(); // elseif (nanos > 0L) // 如果设置了超时,调用Contion.awaitNanos(nanos),将线程放入等待队列 nanos = trip.awaitNanos(nanos); } catch (InterruptedException ie) { if (g == generation && ! g.broken) { breakBarrier(); throw ie; } else { // We're about to finish waiting even if we had not // been interrupted, so this interrupt is deemed to // "belong" to subsequent execution. Thread.currentThread().interrupt(); } }
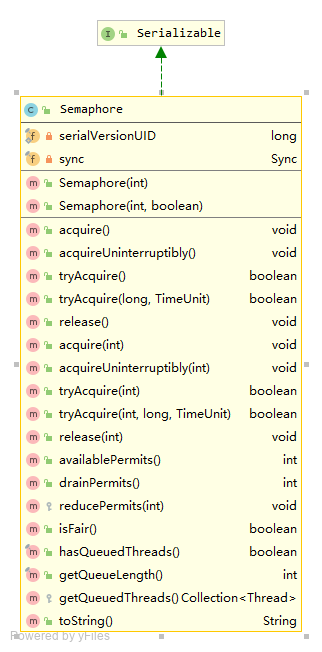
/** * 非公平获取 */ finalintnonfairTryAcquireShared(int acquires){ for (;;) { int available = getState(); int remaining = available - acquires; if (remaining < 0 || compareAndSetState(available, remaining)) return remaining; } }
protectedfinalbooleantryReleaseShared(int releases){ for (;;) { int current = getState(); int next = current + releases; if (next < current) // overflow thrownew Error("Maximum permit count exceeded"); if (compareAndSetState(current, next)) returntrue; } }
finalvoidreducePermits(int reductions){ for (;;) { int current = getState(); int next = current - reductions; if (next > current) // underflow thrownew Error("Permit count underflow"); if (compareAndSetState(current, next)) return; } }
finalintdrainPermits(){ for (;;) { int current = getState(); if (current == 0 || compareAndSetState(current, 0)) return current; } } }
protectedinttryAcquireShared(int acquires){ for (;;) { // 首节点才有机会执行 if (hasQueuedPredecessors()) return -1; int available = getState(); int remaining = available - acquires; if (remaining < 0 || compareAndSetState(available, remaining)) return remaining; } } }
protectedbooleantryReleaseShared(int releases){ // Decrement count; signal when transition to zero for (;;) { int c = getState(); if (c == 0) returnfalse; int nextc = c-1; if (compareAndSetState(c, nextc)) return nextc == 0; } } }
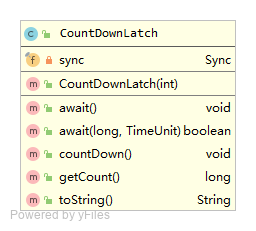
privatefinal Sync sync;
publicCountDownLatch(int count){ if (count < 0) thrownew IllegalArgumentException("count < 0"); this.sync = new Sync(count); }
// 动态规划,状态转移 for (int i = 1; i < n; ++i) { // 不选择第i个物品 for (int j = 0; j <= w; ++j) { if (states[i-1][j] >= 0) { // 此时的状态等于前一个阶段的状态 states[i][j] = states[i-1][j]; } }
// 选择第i个物品 for (int j = 0; j <= w-items[i]; ++j) { if (states[i-1][j] >= 0) { int v = states[i-1][j] + values[i]; // 只存储最大值 if (v > states[i][j+items[i]]) { states[i][j+items[i]] = v; } } } }
// 找出最大值 int maxvalue = -1; for (int j = 0; j <= w; ++j) { if (states[n-1][j] > maxvalue) { maxvalue = states[n-1][j]; } }
return maxvalue; }
最短路径
假设我们有一个 n 乘以 n 的矩阵 w[n][n]。矩阵存储的都是正整数。棋子起始位置在左上角,终止位置在右下角。我们将棋子从左上角移动到右下角。每次只能向右或者向下移动一位。从左上角到右下角,会有很多不同的路径可以走。我们把每条路径经过的数字加起来看作路径的长度。那从左上角移动到右下角的最短短路径长度是多少呢?
回溯算法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
privateint minDist = Integer.MAX_VALUE; publicvoidminDistBT(int i, int j, int dist, int[][] w, int n){ // 到达了 n-1, n-1 这个位置了 if (i == n && j == n) { if (dist < minDist) { minDist = dist; } return; } if (i < n) { // 往下走,更新 i=i+1, j=j minDistBT(i + 1, j, dist+w[i][j], w, n); } if (j < n) { // 往右走,更新 i=i, j=j+1 minDistBT(i, j+1, dist+w[i][j], w, n); } }
/** * 计算背包最大承载重量 * * @param items 物品重量数组 * @param n 物品个数 * @param w 背包可承载重量 * @return 实际背包承载重量 */ publicintcompute(int[] items, int n, int w){ // 记录实际背包承载重量 int[] weight = newint[]{Integer.MIN_VALUE}; // 记录当前状态是否记录过,如果是,就直接返回 boolean[][] mem = newboolean[5][10]; // 递归计算 compute(items, n, w, weight, mem, 0, 0); return weight[0]; }
privatevoidcompute2(int[] items, int n, int w, int[] weight, boolean[][] mem, int i, int cw){ // cw==w 表示装满了,i==n 表示物品都考察完了 if (cw == w || i == n) { if (cw > weight[0]) { weight[0] = cw; } return; }
// 重复状态,直接返回 if (mem[i][cw]) { return; }
// 记录 (i, cw) 这个状态 mem[i][cw] = true;
// 选择不装第 i 个物品 compute2(items, n, w, weight, mem, i + 1, cw);
// 如果还没有满 if (cw + items[i] <= w) { // 选择装第 i 个物品 compute2(items, n, w, weight, mem, i + 1, cw + items[i]); } }
/** * Base of synchronization control for this lock. Subclassed * into fair and nonfair versions below. Uses AQS state to * represent the number of holds on the lock. * * 队列同步器基类,有公平和非公平两个版本 */ abstractstaticclassSyncextendsAbstractQueuedSynchronizer{ privatestaticfinallong serialVersionUID = -5179523762034025860L;
/** * Performs {@link Lock#lock}. The main reason for subclassing * is to allow fast path for nonfair version. */ abstractvoidlock();
/** * Performs non-fair tryLock. tryAcquire is implemented in * subclasses, but both need nonfair try for trylock method. * * 公平和非公平子类中,tryLock都会执行非公平获取锁 */ finalbooleannonfairTryAcquire(int acquires){ final Thread current = Thread.currentThread(); int c = getState(); // 等于0时,表示还没线程获取到该锁 if (c == 0) { if (compareAndSetState(0, acquires)) { setExclusiveOwnerThread(current); returntrue; } } // 如果是已经获取到锁的线程,自增并重置state elseif (current == getExclusiveOwnerThread()) { int nextc = c + acquires; if (nextc < 0) // overflow thrownew Error("Maximum lock count exceeded"); setState(nextc); returntrue; } // 其它线程不可再获取锁 returnfalse; }
protectedfinalbooleantryRelease(int releases){ int c = getState() - releases; if (Thread.currentThread() != getExclusiveOwnerThread()) thrownew IllegalMonitorStateException(); boolean free = false; if (c == 0) { free = true; setExclusiveOwnerThread(null); } setState(c); return free; }
protectedfinalbooleanisHeldExclusively(){ // While we must in general read state before owner, // we don't need to do so to check if current thread is owner return getExclusiveOwnerThread() == Thread.currentThread(); }
final ConditionObject newCondition(){ returnnew ConditionObject(); }
/** * Reconstitutes the instance from a stream (that is, deserializes it). */ privatevoidreadObject(java.io.ObjectInputStream s) throws java.io.IOException, ClassNotFoundException { s.defaultReadObject(); setState(0); // reset to unlocked state } }
/** * Performs lock. Try immediate barge, backing up to normal * acquire on failure. */ finalvoidlock(){ if (compareAndSetState(0, 1)) setExclusiveOwnerThread(Thread.currentThread()); else acquire(1); }
/** * Fair version of tryAcquire. Don't grant access unless * recursive call or no waiters or is first. */ protectedfinalbooleantryAcquire(int acquires){ final Thread current = Thread.currentThread(); int c = getState(); // c=0意味着“锁没有被任何线程锁拥有”, if (c == 0) { // 若“锁没有被任何线程锁拥有” // 则判断“当前线程”是不是CLH队列中的第一个线程线程 // 若是的话,则获取该锁,设置锁的状态,并切设置锁的拥有者为“当前线程” if (!hasQueuedPredecessors() && compareAndSetState(0, acquires)) { setExclusiveOwnerThread(current); returntrue; } } elseif (current == getExclusiveOwnerThread()) { int nextc = c + acquires; if (nextc < 0) thrownew Error("Maximum lock count exceeded"); setState(nextc); returntrue; } returnfalse; } }