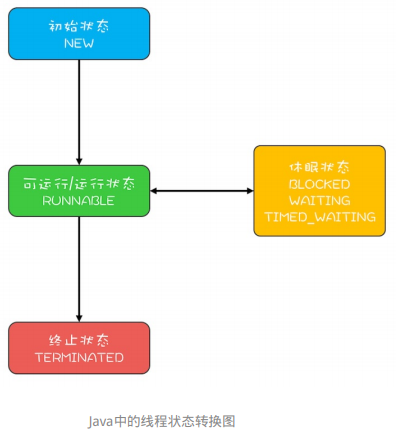
在Java8中,CompletableFuture提供了非常强大的Future的扩展功能,可以帮助我们简化异步编程的复杂性,并且提供了函数式编程的能力,可以通过回调的方式处理计算结果,也提供了转换和组合CompletableFuture的方法。
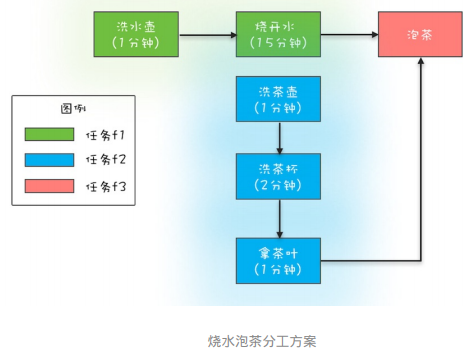
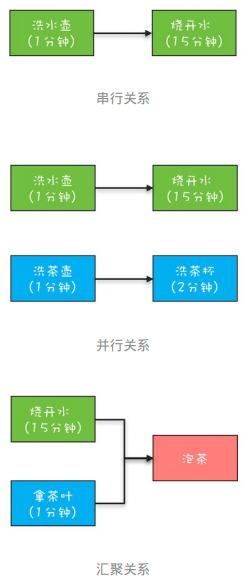
使用示例 为了领略CompletableFuture异步编程的优势,这里我们用CompletableFuture来模拟烧水泡茶程序。在下面的程序中,我们分了3个任务:任务1负责洗水壶、烧开水,任务2负责洗茶壶、洗茶杯和拿茶叶,任务3负责泡茶。其中任务3要等待任务1和任务2都完成后才能开始。这个分工如下图所示:
下面是实现代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 @Test public void makeTea () CompletableFuture<Void> future1 = CompletableFuture.runAsync(() -> { System.out.println("T1:洗⽔壶..." ); sleep(1 , TimeUnit.SECONDS); System.out.println("T1:烧开⽔..." ); sleep(15 , TimeUnit.SECONDS); }); CompletableFuture<String> future2 = CompletableFuture.supplyAsync(() -> { System.out.println("T2:洗茶壶..." ); sleep(1 , TimeUnit.SECONDS); System.out.println("T2:洗茶杯..." ); sleep(2 , TimeUnit.SECONDS); System.out.println("T2:拿茶叶..." ); sleep(1 , TimeUnit.SECONDS); return "⻰井" ; }); CompletableFuture<String> future3 = future1.thenCombine(future2, (result1, result2) -> { System.out.println("T1:拿到茶叶:" + result2); System.out.println("T1:泡茶..." ); return "上茶:" + result2; }); System.out.println(future3.join()); } private void sleep (int t, TimeUnit unit) try { unit.sleep(t); } catch (InterruptedException e) { } }
观察代码不难发现:
无需手工维护线程,没有繁琐的手工维护线程的工作,给任务分配线程的工作也不需要我们关注;
语义更清晰,例如future3 = future1.thenCombine(future2, (result1, result2) -> {})能够清晰地表述“任务3要等待任务1和任务2都完成后才能开始”;
代码更简练并且专注于业务逻辑,几乎所有代码都是业务逻辑相关的。
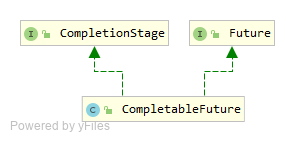
UML
CompletableFuture同时实现了Future接口和CompletionStage接口。Future接口比较好理解,它代表一个异步计算的结果,并且提供了一些方法来让调用者检测异步过程是否完成,或者取得异步计算的结果,或者取消正在执行的异步任务。CompletionStage接口则有点复杂(里面定义了38个方法),在后面会单独介绍。
创建 创建CompletableFuture对象主要是通过调用以下4个静态方法:
1 2 3 4 5 6 7 static CompletableFuture<Void> runAsync (Runnable runnable) static <U> CompletableFuture<U> supplyAsync (Supplier<U> supplier) ;static CompletableFuture<Void> runAsync (Runnable runnable, Executor executor) static <U> CompletableFuture<U> supplyAsync (Supplier<U> supplier, Executor executor) ;
runAsync与supplyAsync之间的区别是:Runnable接口的run()方法没有返回值,而Supplier接口的get()方法是有返回值的;前两个方法和后两个方法的区别在于:后两个方法可以指定线程池参数。
默认情况下,CompletableFuture会使用公共的ForkJoinPool线程池,这个线程池默认创建的线程数是CPU的核数(可以通过JVM option:-Djava.util.concurrent.ForkJoinPool.common.parallelism来设置ForkJoinPool线程池的线程数)。如果所有CompletableFuture共享一个线程池,那么一旦有任务执行一些很慢的I/O操作,就会导致线程池中所有线程都阻塞在I/O操作上,从而造成线程饥饿,进而影响整个系统的性能。所以,强烈建议大家要根据不同的业务类型创建不同的线程池,以避免互相干扰。
创建完CompletableFuture对象之后,会自动地异步执行runnable.run()方法或者supplier.get()方法,对于一个异步操作,我们需要关注两个问题:一个是异步操作什么时候结束,另一个是如何获取异步操作的执行结果。因为CompletableFuture类实现了Future接口,所以这两个问题我们为都可以通过Future接口来解决。另外,CompletableFuture类还实现了CompletionStage接口,这个接口内容实在是太丰富了,接口里的方法我们该如何理解呢?
CompletionStage 我们可以站在分工的角度类比一下工作流。任务是有时序关系的,比如有串行关系 、并行关系 、汇聚关系 等。以前面烧水泡茶的例子来说明,其中洗水壶和烧开水就是串行关系,洗水壶、烧开水和洗茶壶、洗茶杯这两组任务之间就是并行关系,而烧开水、拿茶叶和泡茶就是汇聚关系。
CompletionStage接口可以清晰地描述任务之间的这种时序关系,例如前面提到的future3 = future1.thenCombine(future2, (result1, result2) -> {})描述的就是一种汇聚关系。烧水泡茶程序中的汇聚关系是一种AND聚合关系,这里的AND指的是所有依赖的任务(烧开水和拿茶叶)都完成后才开始执行当前任务(泡茶)。既然有AND聚合关系,那就一定还有OR聚合关系,所谓OR指的是依赖的任务只要有一个完成就可以执行当前任务。CompletionStage接口如何描述串行关系、AND聚合关系、OR聚合关系以及异常处理。
串行关系 CompletionStage接口里面描述串行关系,主要是thenApply、thenAccept、thenRun和thenCompose系列的接口。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 <U> CompletionStage<U> thenApply (Function<? super T,? extends U> fn) ; <U> CompletionStage<U> thenApplyAsync (Function<? super T,? extends U> fn) ; <U> CompletionStage<U> thenApplyAsync (Function<? super T,? extends U> fn, Executor executor) ; CompletionStage<Void> thenAccept (Consumer<? super T> action) ;CompletionStage<Void> thenAcceptAsync (Consumer<? super T> action) ;CompletionStage<Void> thenAcceptAsync (Consumer<? super T> action, Executor executor) ;CompletionStage<Void> thenRun (Runnable action) ;CompletionStage<Void> thenRunAsync (Runnable action) ;CompletionStage<Void> thenRunAsync (Runnable action, Executor executor) ;<U> CompletionStage<U> thenCompose (Function<? super T, ? extends CompletionStage<U>> fn) ; <U> CompletionStage<U> thenComposeAsync (Function<? super T, ? extends CompletionStage<U>> fn) ; <U> CompletionStage<U> thenComposeAsync (Function<? super T, ? extends CompletionStage<U>> fn, Executor executor) ;
需要注意的是thenCompose系列方法,这个系列的方法会新创建出一个子流程,最终结果和thenApply系列是相同的。
AND汇聚关系 CompletionStage接口里面描述AND汇聚关系,主要是thenCombine、thenAcceptBoth和runAfterBoth系列的接口。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 <U,V> CompletionStage<V> thenCombine (CompletionStage<? extends U> other, BiFunction<? super T,? super U,? extends V> fn) ; <U,V> CompletionStage<V> thenCombineAsync (CompletionStage<? extends U> other, BiFunction<? super T,? super U,? extends V> fn) ; <U,V> CompletionStage<V> thenCombineAsync (CompletionStage<? extends U> other, BiFunction<? super T,? super U,? extends V> fn, Executor executor) ; <U> CompletionStage<Void> thenAcceptBoth (CompletionStage<? extends U> other, BiConsumer<? super T, ? super U> action) ; <U> CompletionStage<Void> thenAcceptBothAsync (CompletionStage<? extends U> other, BiConsumer<? super T, ? super U> action) ; <U> CompletionStage<Void> thenAcceptBothAsync (CompletionStage<? extends U> other, BiConsumer<? super T, ? super U> action, Executor executor) ; CompletionStage<Void> runAfterBoth (CompletionStage<?> other, Runnable action) ;CompletionStage<Void> runAfterBothAsync (CompletionStage<?> other, Runnable action) ;CompletionStage<Void> runAfterBothAsync (CompletionStage<?> other, Runnable action, Executor executor) ;
OR汇聚关系 CompletionStage接口里面描述OR汇聚关系,主要是applyToEither、acceptEither和runAfterEither系列的接口。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 <U> CompletionStage<U> applyToEither (CompletionStage<? extends T> other, Function<? super T, U> fn) ; <U> CompletionStage<U> applyToEitherAsync (CompletionStage<? extends T> other, Function<? super T, U> fn) ; <U> CompletionStage<U> applyToEitherAsync (CompletionStage<? extends T> other, Function<? super T, U> fn, Executor executor) ; CompletionStage<Void> acceptEither (CompletionStage<? extends T> other, Consumer<? super T> action) ;CompletionStage<Void> acceptEitherAsync (CompletionStage<? extends T> other, Consumer<? super T> action) ;CompletionStage<Void> acceptEitherAsync (CompletionStage<? extends T> other, Consumer<? super T> action, Executor executor) ;CompletionStage<Void> runAfterEither (CompletionStage<?> other, Runnable action) ;CompletionStage<Void> runAfterEitherAsync (CompletionStage<?> other, Runnable action) ;CompletionStage<Void> runAfterEitherAsync (CompletionStage<?> other, Runnable action, Executor executor) ;
异常处理 CompletionStage接口给我们提供的方案非常简单,比try{}catch{}还要简单,下面是相关的方法,使用这些方法进行异常处理和串行操作是一样的,都支持链式编程方式。
1 2 3 4 5 6 7 8 9 10 11 12 13 CompletionStage<T> exceptionally (Function<Throwable, ? extends T> fn) ;CompletionStage<T> whenComplete (BiConsumer<? super T, ? super Throwable> action) ;CompletionStage<T> whenCompleteAsync (BiConsumer<? super T, ? super Throwable> action) ;CompletionStage<T> whenCompleteAsync (BiConsumer<? super T, ? super Throwable> action, Executor executor) ;<U> CompletionStage<U> handle (BiFunction<? super T, Throwable, ? extends U> fn) ; <U> CompletionStage<U> handleAsync (BiFunction<? super T, Throwable, ? extends U> fn) ; <U> CompletionStage<U> handleAsync (BiFunction<? super T, Throwable, ? extends U> fn, Executor executor) ;