检测消息丢失的方法
如果是 IT 基础设施比较完善的公司,一般都有分布式链路追踪系统,使用类似的追踪系统可以很方便地追踪每一条消息。如果没有这样的追踪系统,那么我们可以利用消息队列的有序性来验证消息丢失。
原理非常简单,在 Producer 端,我们给每个发出的消息附加一个连续递增的序号,然后在 Consumer 端来检查这个序号的连续性。
如果没有消息丢失,Consumer 收到消息的序号必然是连续递增的,或者说收到的消息,其中的序号必然是上一条消息的序号 +1。如果检查到序号不连续,那就是丢消息了。还可以通过缺失的序号来确定丢失的是那条消息,方便进一步排查原因。
大多数消息队列的客户端都支持拦截器机制,我们可以利用这个拦截器机制,在 Producer 发送消息之前的拦截器中将序号注入到消息中,在 Consumer 收到消息的拦截器中检测序号的连续性,这样实现的好处是消息检测的代码不会侵入到我们的业务代码中,待我们的系统稳定后,也方便将这部分检测的逻辑关闭或者删除。
如果是在一个分布式系统中实现这个检测方法,有几个问题需要我们注意。
首先,像 Kafka 这样的消息队列,它是不保证在 Topic 上的严格顺序的,只能保证分区上的消息是有序的,所以我们在发消息的时候必须要指定分区,并且,在每个分区单独检测消息序号的连续性。
然后,如果我们系统中 Producer 是多实例的,由于并不好协调多个 Producer 之间的发送顺序,所以也需要每个 Producer 分别生成各自的消息序号,并且需要附加上 Producer 的标识,在 Consumer 端按照每个 Producer 分别来检测序号的连续性。
另外,Consumer 实例的数量最好和分区数量一致,做到 Consumer 和分区一一对应,这样会比较方便地在 Consumer 内检测消息序号的连续性。
确保消息可靠传递
从消息的生产到消费,可以划分以下三个阶段: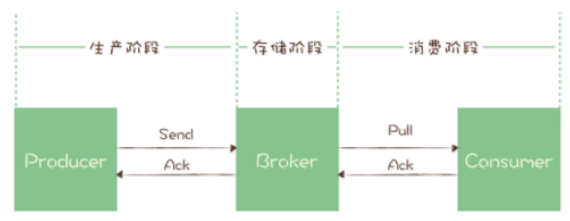
- 生产阶段:从消息在 Producer 创建出来,经过网络传输发送到 Broker 端。
- 存储阶段:消息在 Broker 端存储,如果是集群,消息会在这个阶段被复制到其它的副本上。
- 消费阶段:Consumer 从 Broker 上拉取消息,经过网络传输发送到 Consumer 上。
生产阶段
在生产阶段,消息队列通过最常用的请求确认机制,来保证消息的可靠传递:当我们的代码调用发消息方法时,消息队列的客户端会把消息发送到 Broker,Broker 收到消息后,会给客户端返回一个确认响应,表明消息已经收到了。客户端收到相应后,完成了一次正常消息的发送。
只要 Producer 收到了 Broker 的确认响应,就可以保证消息在生产阶段不会丢失。
在生产方可以设置 retries 属性,这样当生产者长时间没收到发送确认响应后进行自动重试,如果重试后依然失败,就会以返回值或者异常的方式告知用户。
如果要严格保证消息不丢失,还需要设置 acks = all,并保证集群中 broker 的数目大于 2。
我们在编写发送消息代码时,需要注意,正确处理返回值或者捕获异常,就可以保证这个阶段的消息不会丢失。
1 | /** |
存储阶段
在存储阶段,正常情况下,只要 Broker 正常运行,就不会出现丢失消息的问题,但是如果 Broker 出现了故障,比如进程死掉了或者服务器宕机了,还可以可能会丢失消息的。
对于单个节点的 Broker,需要配置 Broker 参数,在收到消息后,将消息写入磁盘后再给 Producer 返回确认响应,这样即使发生宕机,由于消息已经被写入磁盘,就不会丢失消息,恢复后还可以继续消费。(不过这种同步刷盘的方式效率很低)
如果 Broker 是由多个节点组成的集群,需要将 Broker 集群配置成:至少将消息发送到 2 个以上的节点,再给客户端回复发送确认响应。这样当某个 Broker 宕机时,其它 Broker 可以替代宕机的 Broker,也不会发生消息丢失。
另外,在 Broker 端,我们还需要设置以下参数的值:
unclean.leader.election.enable = false
它控制的是哪些 Broker 有资格竞选分区的 Leader。如果一个Broker落后原先的 Leader 太多,那么它一旦成为新的 Leader,必然会造成消息的丢失。故一般都要将该参数设置成 false,即不允许这种情况的发生。replication.factor >= 3
它控制的是将消息多保存几份,毕竟目前防止消息丢失的主要机制就是冗余。min.insync.replicas > 1
它控制的是消息至少要被写入到多少个副本才算是“已提交”。设置成大于 1 可以提升消息持久性。在实际环境中千万不要使用默认值 1。
消费阶段
消费阶段采用和生产阶段类似的确认机制来保证消息的可靠传递,客户端从 Broker 拉去消息后,执行用户的消费业务逻辑,成功后,才会给 Broker 发送消费确认响应。如果 Broker 没有收到确认响应,下次拉消息的时候还会返回同一条消息,确保消息不会在网络传输过程中丢失,也不会因为客户端在执行消费逻辑中出错导致丢失。
我们在编写消费代码时需要注意的是,不要在收到消息后就立即发送消费确认,而是应该在执行完所有消费业务逻辑之后,再发送消费确认。这就需要设置 enable.auto.commit = false 来关闭位移自动提交。