Redis 采用的是基于内存的、单线程模型的 KV 数据库。官方提供的数据是可以达到 10w+ 的 QPS。这个数据不比采用单进程多线程的同样基于内存的 KV 数据库 Memcached 差。
理解单线程模型
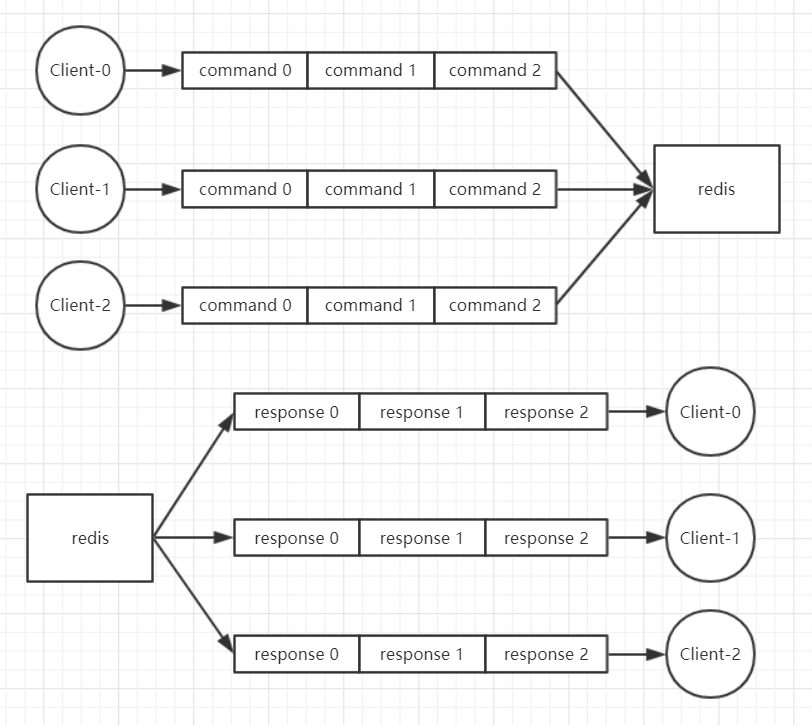
- Redis 会将每个客户端都关联一个指令队列。客户端的指令通过队列来按顺序处理,先到先服务。
- 在一个客户端的指令队列中的指令是顺序执行的,但是多个指令队列中的指令是无法保证顺序的,例如执行完 client-0 的队列中的 command-0 后,接下去是执行哪个队列中的第一个指令是无法确定的,但是肯定不会同时执行两个指令。
- Redis 同样也会为每个客户端关联一个响应队列,通过响应队列来顺序地将指令的返回结果回复给客户端。
- 同样,一个响应队列中的消息可以顺序的回复给客户端,多个响应队列之间是无法保证顺序的。
- 所有的客户端的队列中的指令或者响应,Redis 每次都只能处理一个,同一时间绝对不会处理超过一个指令或者响应。
为什么 Redis 使用单线程模型还能保证高性能
纯内存访问
Redis 将所有数据放在内存中,内存的响应时长大约为 100 纳秒,这是 Redis 的 QPS 过万的重要基础。非阻塞式 IO
什么是阻塞式 IO
当我们调用 Scoket 的读写方法,默认它们是阻塞的。
read() 方法要传递进去一个参数 n,表示读取这么多字节后再返回,如果没有读够 n 字节线程就会阻塞,直到新的数据到来或者连接关闭了, read 方法才可以返回,线程才能继续处理。
write() 方法会首先把数据写到系统内核为 Scoket 分配的写缓冲区中,当写缓存区满溢,即写缓存区中的数据还没有写入到磁盘,就有新的数据要写道写缓存区时,write() 方法就会阻塞,直到写缓存区中有空闲空间。什么是非阻塞式 IO
非阻塞 IO 在 Scoket 对象上提供了一个选项 Non_Blocking ,当这个选项打开时,读写方法不会阻塞,而是能读多少读多少,能写多少写多少。
能读多少取决于内核为 Scoket 分配的读缓冲区的大小,能写多少取决于内核为 Scoket 分配的写缓冲区的剩余空间大小。读方法和写方法都会通过返回值来告知程序实际读写了多少字节数据。
有了非阻塞 IO 意味着线程在读写 IO 时可以不必再阻塞了,读写可以瞬间完成然后线程可以继续干别的事了。
IO 多路复用
“多路”指的是多个网络连接,“复用”指的是复用同一个线程。采用多路 I/O 复用技术可以让单个线程高效的处理多个连接请求(尽量减少网络 IO 的时间消耗)。可以直接理解为:单线程的原子操作,避免上下文切换的时间和性能消耗;加上对内存中数据的处理速度,很自然的提高 Redis 的吞吐量数据结构简单
单线程可以简化数据结构和算法的实现。并发数据结构实现不但困难而且开发测试比较麻。
Redis 全程使用 hash 结构,读取速度快,还有一些特殊的数据结构,对数据存储进行了优化,如压缩表对短数据进行压缩存储,再如跳表使用有序的数据结构加快读取的速度。单线程避免了线程切换和竞态产生的消耗
单线程避免了线程切换和竞态产生的消耗,对于服务端开发来说,锁和线程切换通常是性能杀手。
单线程的问题
- 对于每个命令的执行时间是有要求的。如果某个命令执行过长,会造成其他命令的阻塞,所以 redis 适用于那些需要快速执行的场景。
- 无法发挥多核CPU性能,不过可以通过在单机开多个 Redis 实例来完善。

