持久化原理
Kafka 依赖文件系统来存储和缓存消息。
对于硬盘的传统观念是硬盘总是很慢,基于文件系统的架构能否提供优异的性能?实际上硬盘的快慢完全取决于使用方式。
为了提高性能,现代操作系统往往使用内存作为磁盘的缓存,所有的磁盘读写操作都会经过这个缓存,所以如果程序在线程中缓存了一份数据,实际在操作系统的缓存中还有一份,这等于存了两份数据。
同时 Kafka 基于 JVM 内存有以下缺点:
- 对象的内存开销非常高,通常是要存储的数据的两倍甚至更高
- 随着堆内数据的增加,GC 的速度越来越慢
实际上磁盘的线性写入的性能远远大于任意位置写的性能,线性读写由操作系统进行了大量优化(read-ahead、write-behind 等技术),甚至比随机的内存读写更快。所以与常见的数据缓存在内存中然后刷到磁盘的设计不同,Kafka 直接将数据写到了文件系统的日志中:
- 写操作:将数据顺序追加到文件中
- 读操作:从文件中读取
这样实现的好处:
- 读操作不会阻塞写操作和其他操作,数据大小不对性能产生影响
- 硬盘空间相对于内存空间容量限制更小
- 线性访问磁盘,速度快,可以保存更长的时间,更稳定
持久化文件
一个 Topic 被分成多 Partition,每个 Partition 在存储层面是一个 append-only 日志文件,属于一个 Partition 的消息都会被直接追加到日志文件的尾部,每条消息在文件中的位置称为 offset(偏移量)。
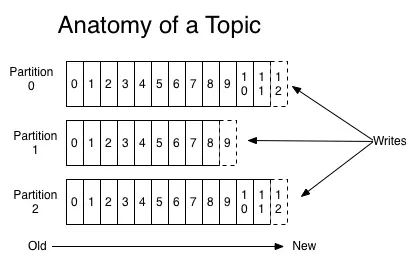
日志文件由“日志条目(log entries)”序列组成,每一个日志条目包含一个 4 字节整型数(值为 N),其后跟 N 个字节的消息体。每条消息都有一个当前 Partition 下唯一的 64 字节的 offset,标识这条消息的起始位置。消息格式如下:
1 | On-disk format of a message |
Kafka 持久化日志视图: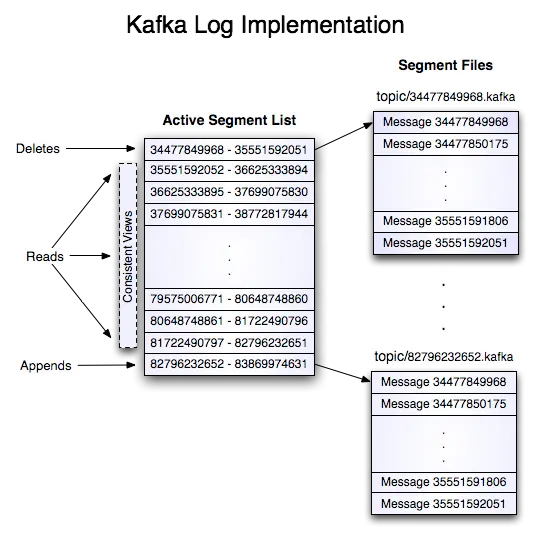
写
日志文件允许串行附加,并且总是附加到最后一个文件。当文件达到配置指定的大小(log.segment.bytes = 1073741824 (bytes))时,就会被滚动到一个新文件中(每个文件称为一个 segment file)。
日志有两个配置参数:
- M 强制操作系统将文件刷新到磁盘之前写入的消息数
- S 强制操作系统将文件刷新到磁盘之前的时间(秒)
在系统崩溃的情况下,最多会丢失 M 条消息或 S 秒的数据。
读
通过给出消息的偏移量(offset)和最大块大小(S)来读取数据。返回一个缓冲区为 S 大小的消息迭代器,S 应该大于任何单个消息的大小,如果消息异常大,则可以多次重试读取,每次都将缓冲区大小加倍,直到成功读取消息为止。可以指定最大消息大小和缓冲区大小,以使服务器拒绝大于某个大小的消息。读取缓冲区可能以部分消息结束,这很容易被大小分隔检测到。
读取指定偏移量的数据时,需要首先找到存储数据的 segment file,由全局偏移量计算 segment file 中的偏移量,然后从此位置开始读取。
删除
消息数据随着 segment file 一起被删除。Log manager 允许可插拔的删除策略来选择哪些文件符合删除条件。当前策略为删除修改时间超过 N 天前的任何日志,或者是保留最近的 N GB 的数据。
为了避免在删除时阻塞读操作,采用了 copy-on-write 技术:删除操作进行时,读取操作的二分查找功能实际是在一个静态的快照副本上进行的。
文件索引
上面提到日志文件非由一个文件构成,而是分成多个 segment(文件达到一定大小时进行滚动),每个 segment 名为该 segment 第一条消息的 offset 和 “.kafka” 组成。另外会有一个索引文件,标明了每个 segment 下包含的日志条目的 offset 范围。
1 | |- 000000000000000400.index |
有了索引文件,消费者可以从 Kafka 的任意可用偏移量位置开始读取消息。索引也被分成片段,所以在删除消息时,也可以删除相应的索引。Kafka 不维护索引的校验和,如果索引出现损坏,Kafka 会通过重新读取消息来重新生成索引。

