JMS 规范
JMS 规范定义了两种消息模型:点对点(point to point, queue)和发布/订阅(publish/subscribe, topic)。
点对点(point to point, queue)
生产者生产消息发送到 queue 中,然后消费者从 queue 中取出并且消费消息。 这里要注意:消息被消费以后,queue 中不再有存储, 所以消费者不可能消费已经被消费的消息。queue 支持存在多个消费者,但是对一个消息而言,只会有一个消费者可以消费。
点对点模型示意图如下: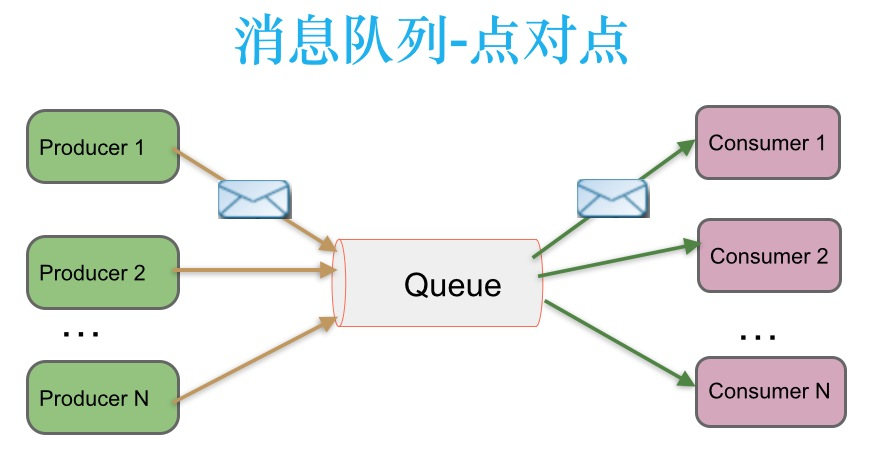
发布/订阅(publish/subscribe, topic)
在发布-订阅消息系统中,消息被持久化到一个 topic 中。与点对点消息系统不同的是,消费者可以订阅一个或多个 topic,消费者可以消费该 topic 中所有的数据,同一条数据可以被多个消费者消费,数据被消费后不会立马删除。在发布-订阅消息系统中,消息的生产者称为发布者,消费者称为订阅者。
发布/订阅模型示意图如下: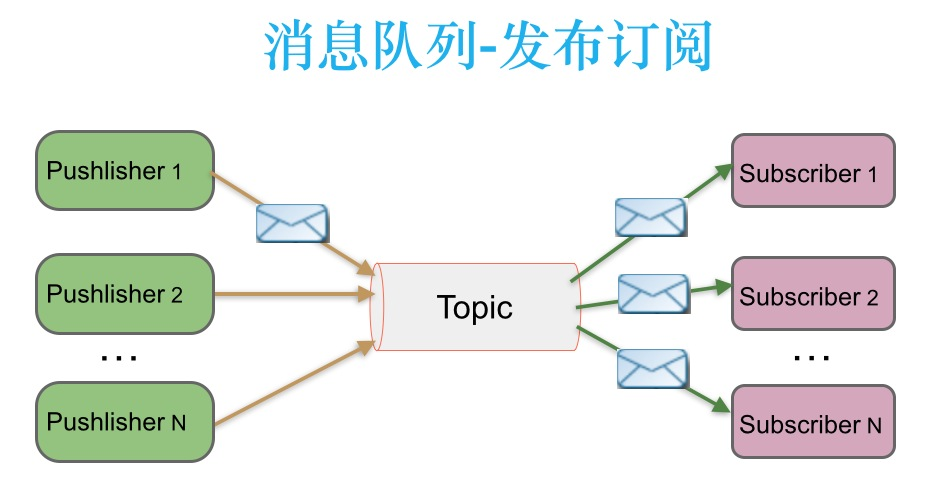
Kafka 消息模型
从 JMS规范上来说,Kafka 没有实现点对点模型,只实现了发布/订阅模型。不过在这种发布/订阅模型中,如果只有一个订阅者,那它和点对点模型就基本是一样的了。也就是说,发布/订阅模型在功能层面上是可以兼容点对点模型的。
在 Kafka 消息模型中,每个主题包含多个分区,通过多个分区来实现多实例并行生产和消费。需要注意的是,Kafka 只在分区上保证消息的有序性,主题层面是无法保证消息的严格顺序的。
在 Kafka 中,订阅者的概念是通过消费组(Consumer Group)来体现的。每个消费组都消费主题中一份完整的消息,不同消费组之间消费进度彼此不受影响,也就是说,一条消息被 Consumer Group1 消费过,也会再给Consumer Group2消费。
消费组中包含多个消费者,同一个组内的消费者是竞争消费的关系,每个消费者负责消费组内的一部分消息。如果一条消息被消费者 Consumer1 消费了,那同组的其他消费者就不会再收到这条消息。
在 Topic 的消费过程中,由于消息需要被不同的组进行多次消费,所以消费完的消息并不会立即被删除,这就需要 Kafka 为每个消费组在每个分区上维护一个消费位置(Consumer Offset),这个位置之前的消息都被消费过,之后的消息都没有被消费过,每成功消费一条消息,消费位置就加一。
Kafka 消息模型示意图如下: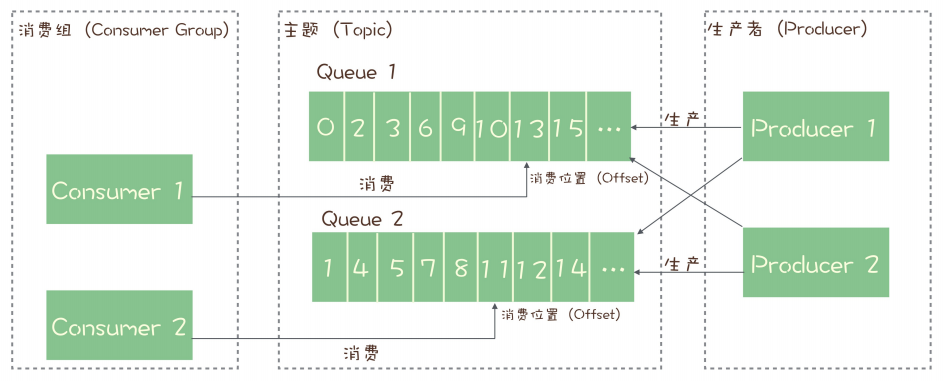
在本文最后,需要再说明下为何 Kafka 会引入分区这个概念:
在生产端,生产者先将消息发送给服务端,也就是Broker,服务端在收到消息并将消息写入主题或者队列中后,会给生产者发送确认的响应。如果生产者没有收到服务端的确认或者收到失败的响应,则会重新发送消息;在消费端,消费者在收到消息并完成自己的消费业务逻辑(比如,将数据保存到数据库中)后,也会给服务端发送消费成功的确认,服务端只有收到消费确认后,才认为一条消息被成功消费,否则它会给消费者重新发送这条消息,直到收到对应的消费成功确认。这个确认机制很好地保证了消息传递过程中的可靠性,但是,引入这个机制在消费端带来了一个不小的问题。什么问题呢?
为了确保消息的有序性,在某一条消息被成功消费之前,下一条消息是不能被消费的,否则就会出现消息空洞,违背了有序性这个原则。也就是说,每个主题在任意时刻,至多只能有一个消费者实例在进行消费,那就没法通过水平扩展消费者的数量来提升消费端总体的消费性能。为了解决这个问题,Kafka 在主题下面增加了队列的概念。

