概念
Fork/Join 框架是 Java 7 提供的一个用于并行执行任务的框架,是一个把大任务分割成若干个小任务,最终汇总每个小任务结果后得到大任务结果的框架。
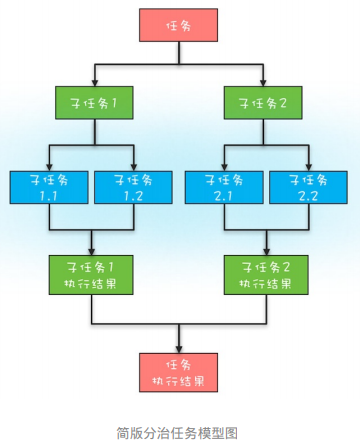
Fork 就是把一个大任务切分为多干个子任务并行的执行,Join 就是合并这些子任务的执行结果,最后得到这个大任务的结果。Fork/Join 的运行流程图如下所示:
实现原理
ForkJoinPool
ForkJoinPool 本质上也是一个生产者-消费者的实现,但是更加智能。ThreadPoolExecutor 内部只有一个任务队列,而 ForkJoinPool 内部有多个任务队列,当
我们通过 ForkJoinPool 的 invoke() 或者 submit() 方法提交任务时,ForkJoinPool 根据一定的路由规则把任务提
交到一个任务队列中,如果任务在执行过程中会创建出子任务,那么子任务会提交到工作线程对应的任务队
列中。
工作窃取算法
ForkJoinPool 支持一种叫做“任务窃取”的机制,如果工作线程空闲了,那它可以“窃取”其他工作任务队列里的任务。如此一来,所有的工作线程都不会闲下来了。
ForkJoinPool 中的任务队列采用的是双端队列,工作线程正常获取任务和“窃取任务”分别是从任务队列不同的端消费,这样能避免很多不必要的数据竞争。
- 优点:充分利用线程进行并行计算,减少了线程间的竞争
- 缺点:在某些情况下还是存在竞争,比如双端队列里只有一个任务时。并且该算法会消耗更多的系统资源,比如创建多个线程和多个双端队列。
使用
Fork/Join 是一个并行计算的框架,主要就是用来支持分治任务模型的,这个计算框架里的 Fork 对应的是分治任务模型里的任务分解,Join 对应的是结果合并。Fork/Join 计算框架主要包含两部分,一部分是分治任务的线程池 ForkJoinPool,另一部分是分治任务 ForkJoinTask。这两部分的关系类似于 ThreadPoolExecutor 和 Runnable 的关系,都可以理解为提交任务到线程池,只不过分治任务有自己独特类型 ForkJoinTask。
ForkJoinTask 是一个抽象类,它的方法有很多,最核心的是 fork() 方法和 join() 方法,其中 fork() 方法会异步地执行一个子任务,而 join() 方法则会阻塞当前线程来等待子任务的执行结果。ForkJoinTask 有两个子类:RecursiveAction 和 RecursiveTask,通过名字你就应该能知道,它们都是用递归的方式来处理分治任务的。这两个子类都定义了抽象方法 compute(),不过区别是 RecursiveAction 定义的 compute() 没有返回值,而 RecursiveTask 定义的 compute() 方法是有返回值的。这两个子类也是抽象类,在使用的时候,需要我们定义子类去扩展。
计算斐波那契数列
1 | static void main(String[] args) { |
求和
1 | public static void main(String[] args) throws ExecutionException, InterruptedException { |
Parallel Stream
Java 1.8 提供的 Stream API 里面并行流也是以 ForkJoinPool 为基础的。不过需要注意的是,默认情况下所有的并行流计算都共享一个 ForkJoinPool,这个共享的 ForkJoinPool 默认的线程数是 CPU 的核数;如果所有的并行流计算都是 CPU 密集型计算的话,完全没有问题,但是如果存在 I/O 密集型的并行流计算,那么很可能会因为一个很慢的 I/O 计算而拖慢整个系统的性能。所以建议用不同的 ForkJoinPool 执行不同类型的计算任务。

