背景
如果“为每个任务分配一个线程”,那么当需要创建大量线程时,会有以下问题:
- 线程生命周期的开销非常高
线程的创建与销毁都是需要开销的。如果请求的到达率非常高且请求的处理过程是轻量级的(大多数服务器应用程序就是这种情况),那么为每个请求创建一个新线程将消耗大量的计算资源。 - 资源消耗增加
活跃的线程会消耗系统资源,尤其是内存。如果可运行的线程数量多于可用处理器的数量,那么有些线程将闲置。大量空闲的线程会占用大量内存,给垃圾收集器带来压力,而且大量线程在竞争CPU资源时还将产生其它的性能开销。如果已经有足够多的线程是所有CPU保持忙碌状态,那么再创建更多的宪曾反而会降低性能。 - 稳定性减低
在可创建线程的数量上存在一些限制,如果破坏了这些限制,那么很可能抛出OutOfMemoryError异常。
反之,合理地使用线程池不仅能避免上述问题的发生,还具备以下好处:
- 提高响应速度
当任务到达,任务可以不需要等待线程创建就能立即执行。 - 提高线程的可管理性
使用线程池可以对线程进行统一分配、调优和监控。
实现原理
线程池的主要处理流程如下图所示: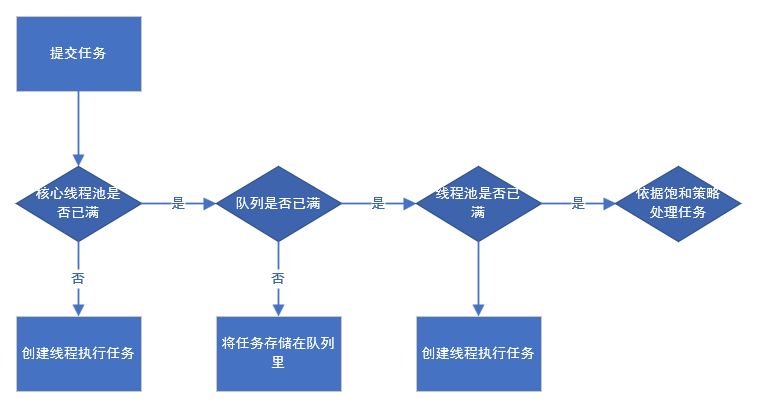
从图中可以看出,当提交一个新任务到线程池时,线程池的处理流程如下:
- 线程池判断核心线程池里的线程是否都在执行任务。如果不是,则创建一个新的工作线程来执行任务;如果是,则进入下个流程。
- 线程池判断工作队列是否已满。如果没有满,则将任务存储在工作队列里;如果满了,则进入下个流程。
- 线程池判判断线程池里的线程是否都处于工作状态。如果不是,则创建一个新的工作线程来执行任务;如果是,则依据饱和策略来处理这个任务。
使用
创建
线程池提供了以下构造函数:
1 | public ThreadPoolExecutor(int corePoolSize, |
- corePoolSize
线程池的基本大小。
当提交一个任务到线程池时,如果线程池中线程的个数小于corePoolSize,那么即使其它空闲的基本线程能够执行新任务,线程池也会创建新的线程。
如果要提前创建并启动所有的基本线程,可以调用线程池的prestartAllCoreThreads方法。 - maximumPoolSize
线程池允许创建的最大线程数。
如果队列满了,并且已创建的线程数小于maximumPoolSize,则线程池会再创建新的线程执行任务。
需要注意的是,如果使用了无界队列,则该参数就没什么效果。 - keepAliveTime
线程池的工作线程空闲后所能保持存活的时间。
如果任务很多,并且每个任务执行的时间比较短,可以调大时间,以提高线程的利用率。 - unit
线程存活时间的单位,其枚举值有:- DAYS
- HOURS
- MINUTES
- MILLISECONDS
- MICROSECONDS
- NANOSECONDS
- workQueue
用于保存等待执行的任务的阻塞队列,可选的队列实现有:- ArrayBlockingQueue
基于数组结构的有界阻塞队列,此队列按FIFO原则(先进先出)对元素进行排序。 - LinkedBlockingQueue
基于链表结构的阻塞队列,此队列按FIFO原则对元素进行排序,吞吐量通常要高于ArrayBlockingQueue。
静态工厂方法Executors.newFixedThreadPool()和Executors.newSingleThreadExecutor()使用了这个队列。 - SynchronousQueue
不存储元素阻塞队列。每个插入操作必须灯到另一个线程调用移除操作,否则插入操作一直处于阻塞状态,吞吐量通常要高于LinkedBlockingQueue。
静态工厂方法Executors.newCachedThreadPool()使用了这个队列。 - PriorityBlockingQueue
具有优先级的无限阻塞队列。
建议使用有界队列,有界队列能增加系统的稳定性和预警能力。- threadFactory
创建线程的工厂。
可以通过线程工厂给每个创建出来的线程设置更有意义的名字,比如使用guava提供的ThreadFactoryBuilder类:1
new ThreadFactoryBuilder().setNameFormat("xx-task-%d").build();
Executors中定义了默认的实现DefaultThreadFactory:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26static class DefaultThreadFactory implements ThreadFactory {
private static final AtomicInteger poolNumber = new AtomicInteger(1);
private final ThreadGroup group;
private final AtomicInteger threadNumber = new AtomicInteger(1);
private final String namePrefix;
DefaultThreadFactory() {
SecurityManager s = System.getSecurityManager();
group = (s != null) ? s.getThreadGroup() :
Thread.currentThread().getThreadGroup();
namePrefix = "pool-" +
poolNumber.getAndIncrement() +
"-thread-";
}
public Thread newThread(Runnable r) {
Thread t = new Thread(group, r,
namePrefix + threadNumber.getAndIncrement(),
0);
if (t.isDaemon())
t.setDaemon(false);
if (t.getPriority() != Thread.NORM_PRIORITY)
t.setPriority(Thread.NORM_PRIORITY);
return t;
}
}
- threadFactory
- ArrayBlockingQueue
- handler
饱和策略。
当线程池和队列都满了,说明线程池处于饱和状态,那么必须采取某种策略来处理新提交的任务,可选饱和策略有:- AbortPolicy:直接抛出异常。
- DiscardPolicy:不处理,丢弃掉。
- DiscardOldestPolicy:丢弃队列里最近的一个任务,并执行当前任务。
- CallerRunsPolicy:用调用者所在的线程来执行任务。
线程池默认的拒绝策略会throw RejectedExecutionException,这是个运行时异常,对于运行时异常编译器并不强制catch它,所以开发人员很容易忽略。因此默认拒绝策略要慎重使用。如果线程池处理的任务非常重要,建议自定义自己的拒绝策略;并且在实际工作中,自定义的拒绝策略往往和降级策略配合使用。
提交任务
- execute
1
2
3
4
5
6
7/**
* 在将来某个时候执行给定的任务。任务可以在新线程中执行,也可以在现有的池线程中执行。
* 如果无法提交任务供执行,要么是因为此执行器已关闭,要么是因为其容量已达到,则由当前{@code RejectedExecutionHandler}处理该任务。
*
* @param command the task to execute
*/
void execute(Runnable command); - submit
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27/**
* 提交任务并返回一个Future对象
* 一旦任务执行成功,调用Futrue的get方法将会任务执行结果
*
* @param task 提交的任务
* @return a Future representing pending completion of the task
*/
<T> Future<T> submit(Callable<T> task);
/**
* 提交任务并返回一个Future对象
* 一旦任务执行成功,调用Futrue的get方法将会返回给定result
*
* @param task 提交的任务
* @param result 返回值
* @return a Future representing pending completion of the task
*/
<T> Future<T> submit(Runnable task, T result);
/**
* 提交任务并返回一个Future对象
* 一旦任务执行成功,调用Futrue的get方法将会返回null
*
* @param task 提交的任务
* @return a Future representing pending completion of the task
*/
<T> Future<T> submit(Runnable task); - invokeAll/invokeAny
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34/**
* 执行给定任务列表,并当所有任务都执行完毕后,返回Future对象列表
* @param tasks 提交的任务列表
* @return a list of Futures representing the tasks, in the same sequential order as produced by the iterator for the
* given task list, each of which has completed
*/
<T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks) throws InterruptedException;
/**
* 执行给定任务列表,并当所有任务都执行完毕后,返回Future对象列表
* 如果超时,还没有执行完毕的任务会被取消
* @param tasks 提交的任务列表
* @return a list of Futures representing the tasks, in the same sequential order as produced by the iterator for the
* given task list. If the operation did not time out, each task will have completed. If it did time out, some
* of these tasks will not have completed.
*/
T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks, long timeout, TimeUnit unit)
throws InterruptedException;
/**
* 执行给定任务列表,并当其中一个任务执行完毕后,返回Future对象
* @param tasks 提交的任务列表
* @return the result returned by one of the tasks
*/
<T> T invokeAny(Collection<? extends Callable<T>> tasks) throws InterruptedException, ExecutionException;
/**
* 执行给定任务列表,并当其中一个任务执行完毕后,返回Future对象
* 如果超时,抛出TimeoutException
* @param tasks 提交的任务列表
* @return the result returned by one of the tasks
*/
<T> T invokeAny(Collection<? extends Callable<T>> tasks, long timeout, TimeUnit unit)
throws InterruptedException, ExecutionException, TimeoutException;
使用线程池,需要注意异常处理的问题,例如通过ThreadPoolExecutor对象的execute()方法提交任务时,如果任务在执行的过程中出现运行时异常,会导致执行任务的线程终止;不过,最致命的是任务虽然异常了,但是开发人员却获取不到任何通知,这会让开发人员误以为任务都执行得很正常。虽然线程池提供了很多用于异常处理的方法,但是最稳妥和简单的方案还是捕获所有异常并按需处理,我们可以参考下面的示例代码。
1 | try { |
关闭线程池
1 | /** |
- FixedThreadPool的corePoolSize和maximumPoolSize都被设置为参数nThreads的值
- FixedThreadPool的keepAliveTime参数设置为0L,意味着多余的空闲线程会被立即终止
- FixedThreadPool使用无界队列LinkedBlockingQueue作为线程池的工作队列(队列容量为Integer.MAX_VALUE)
- 由于使用无界队列,所以maximumPoolSize和keepAliveTime无效,所以有1和2
- 由于使用无界队列,所以运行中的FixedThreadPool(未执行shutDown()或shutDownNow)不会拒绝任务(不会调用RejectedExecutionHandler.rejected方法)
SingleThreadExecutor
SingleThreadExecutor是使用单个Worker线程的Executor,下面是源码实现:
1 | public static ExecutorService newSingleThreadExecutor() { |
- SingleThreadExecutor的corePoolSize和maximumPoolSize都被设置为1
- SingleThreadExecutor的keepAliveTime参数设置为0L,意味着多余的空闲线程会被立即终止
- SingleThreadExecutor使用无界队列LinkedBlockingQueue作为线程池的工作队列(队列容量为Integer.MAX_VALUE)
- 由于使用无界队列,所以maximumPoolSize和keepAliveTime无效,所以有1和2
- 由于使用无界队列,所以运行中的FixedThreadPool(未执行shutDown()或shutDownNow)不会拒绝任务(不会调用RejectedExecutionHandler.rejected方法)
CachedThreadPool
CachedThreadPool是一个会根据需要创建新线程的线程池,下面是源码实现:
1 | public static ExecutorService newCachedThreadPool() { |
- CachedThreadPool的corePoolSize被设置为0,即corePool为空。
- CachedThreadPool的maximumPoolSize被设置为Integer.MAX_VALUE,即线程池是无界的。
- CachedThreadPool的keepAliveTime参数设置为60L,意味着多余的线程空闲时间超过60秒将会被终止。
- CachedThreadPool使用
SynchronousQueue作为线程池的工作队列,它是一个没有容量的阻塞队列,每个插入操作必须等待另一个线程对应的移除操作,反之亦然。 - 如果任务提交的速度高于线程池中任务执行的速度时,CachedThreadPool会不断地创建新线程。极端情况下,CachedThreadPool会因为创建过多线程而耗尽CPU和内存资源。
CachedThreadPool运行示意图如下:
- 首先执行SynchronousQueue.offer。
- 如果当前线程池中有空闲线程正在执行SynchronousQueue.poll,那么主线程执行的offer操作与空闲线程执行的poll操作配对成功主线程把任务交给空闲线程执行。
- 如果线程池中没有空闲线程,即没有线程执行SynchronousQueue.poll,此时CachedThreadPool会创建一个新线程执行任务。
- 如果执行的是方法SynchronousQueue.poll(long timeout, TimeUnit unit),该操作会让空闲线程最多等待指定的时间,如果指定时间内主线程提交了一个新任务,那么这个线程将执行主线程提交的新任务;否则,这个线程将终止。
监控
如果在系统总大量使用线程池,则有必要对线程池进行监控,方便在出现问题时,可以根据线程池的使用状况快速定位问题。在监控线程池的时候可以使用以下属性:
- taskCount
线程池需要执行的任务数量 - completedTaskCount
线程池在运行过程中已完成的任务数量,小于或等于taskCount - largestPoolSize
线程池里曾经创建过的最大线程数量。通过这个数据可以知道线程池是否曾经瞒过。 - getPoolSize
线程池的线程数量。 - getActiveCount
获取活动的线程数。
另外还能通过继承线程池来自定义线程池,重写线程池的方法,来实现在任务执行前、执行后和线程池关闭前执行一些代码来进行监控。例如,监控任务的平均执行时间、最大执行时间和最小执行时间等。
1 | public class CustomThreadPoolExecutor extends ThreadPoolExecutor { |
配置
要想合理地配置线程池,就必须首先分析任务特性,可以从以下几个角度来分析:
- 任务的性质
CPU密集型任务、IO密集型任务和混合型任务。
CPU密集型任务应配置尽可能少的线程,如配置N(CPU个数)+1个线程。由于IO密集型任务线程并不是一直在执行任务,则应配置尽可能多的线程,如2N个线程。混合型的任务,如果可以拆分,且拆分后的任务的执行时间相差不大,则将其拆分为一个CPU密集型任务和一个IO密集型任务。
可以通过Runtime.getRuntime.availableProcessors()方法获得当前设备地CPU个数。 - 任务的优先级
高、中和低。
优先级不同的任务可以使用优先级队列PriorityBlockingQueue来处理。
需要注意的是,如果一直有优先级高的任务提交到队列里,那么优先级低的任务可能永远不会执行。 - 任务的执行时间
长、中和短。
执行时间不同的任务可以交给不同规模的线程池来处理,或者可以使用优先级队列,让执行时间短的任务先执行。 - 任务的依赖性
是否依赖其它系统资源,如数据库连接。
依赖数据库连接池的任务,因为线程提交SQL后需要等待数据库返回结果,等待的时间越长,则CPU空闲时间就越长,那么线程数应该设置得越大,这样才能更好地利用CPU。
源码分析
首先,看下线程池执行任务的方法execute:
1 | /** |
然后,再看下Worker是怎么执行任务的:
1 | final void runWorker(Worker w) { |
执行示意图


